OpenAI新模型全网实测惊艳来袭!o3缩放图像被玩疯,o4-mini速解Project Euler,碾压人类。AI初创CEO说,OpenAI凭此一役已经重回榜首,甚至有经济学家直言AGI已经来临!
昨夜o3的发布,让人不尽感慨:打了这么久嘴炮的OpenAI,这回终于实实在在拿出了点真东西。
史上首次,模型能够用图像思考,视觉推理达到巅峰。
许多网友实测后,大感惊艳。
o3能不断缩放图像,完成解题、识图,编程任务实测惊人。
还有一大特点,就是速度快!只用2分55秒,它就解决了一道Project Euler问题,速度秒杀任何人类。
甚至可以认为,o3是一个快速版的Deep Search,但不需要20分钟,只需要2分钟。
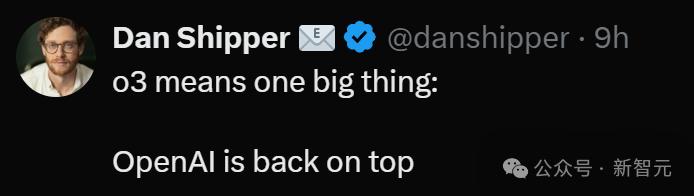
AI初创CEO Dan Shipper表示,o3意味着一件大事——OpenAI已经重回榜首!

经济学家Tyler Cowen甚至直接发文,深感就在今天,AGI已经降临!

缩放图像,被网友玩疯
给出一张图,o3就可以反复缩放和裁剪图像,多小的图,经过这一番操作后都能马上被识别出来。

比如琴架上曲谱里是什么歌,它通过放大图片就能发现:这是「月亮河」。

发给o3一张婴儿车的照片,询问品牌和型号后,它会自动放大靠背上的小标志,经过14次搜索后,找到了正确答案。

还有人给o3发了一张图片,问它这辆车是哪个品牌和型号。

o3一番丝滑操作,多次裁剪图片,不停用Python写代码,然后开始在网上狂搜,仅仅4分钟后,它就找到了正确答案,堪称惊人!




无论是确认饭店名字,还是做出一堆玩具中纸上的谜题,它都游刃有余。


有人让4o来分析y轴上的数字,确认它们是否符合大海捞针测试中的S型分布。

果然,它不仅做到了,甚至还根据这些数字做出了一张图表。



综合解题能力
o3的综合解题能力,让人倍感惊艳。
Layers Itd的联创兼开发主管称,o3实在令他印象太深刻了,因为下图中这个问题,第一次被一个模型一次性解决了!

而o4-mini-high则是和其他模型一样,在几次尝试后才成功解决。
问题看似很简单:红色柱子有多高?
这道题的精髓,无非就是算出物体实际高度和投在地上影子的比例,另外要注意红柱子落在竖直墙上的影长,跟对应部分的实际高度一致。

如此简单的问题,却让很多大模型第一次都折戟了,只有o3顺利做出。

而生物医学教授Derya Unutamz表示,自己被全新的o3模型彻底震撼了!

因为已经提前获得了访问权限,他已经好几天对o3爱不释手。
在他看来,o3就像o1-preview和o1-pro的里程碑,但在各个方面都更聪明、更可靠,甚至可以说,o3的智能水平已经达到或接近天才级别。
它从不产生幻觉,智能体风格工具能轻松处理多步骤任务,还具备非凡的推理能力和精确性,能生成极具洞察力的科学假设。

当Unutamz教授向o3提出极有挑战性的临床或医学问题时,它的回答仿佛来自顶级的专科医生,精确、全面、基于证据、充满智慧。
他表示,o3的诞生,对于科学、医学及很多领域,都是一个彻底的颠覆者。

而最喜欢给新模型测试「水獭难题」的沃顿商学院教授Ethan Mollick,则直接让o3制作了一部关于水獭和飞机的电影。
接到这个指令后,o3虽然没有电影功能,立即自行决定绘制每一帧,然后拼接成gif。这个任务,它一次性顺利完成。

AGI已经降临?
OpenAI的工程师、普林斯顿校友John Hallman,在o3完成训练后提早有了试用新模型的机会,他难掩内心冲动:
o3就是AGI。
虽然还不完美,但在99%的智力评估中,o3模型能击败我、你乃至99%的人类。

经济学家Tyler Cowen,直接发文宣扬:昨天OpenAI发布o3之日,就是AGI降临之日。

他坚信o3就是AGI,但释放AGI潜力,尚需时日:
我认为这是AGI,真的。
试着问它多个问题,然后问问自己:我原本期望AGI有多聪明?
正如我过去所争论的,无论你如何定义AGI,它本身并不是社会事件。我们仍然需要很长时间才能正确地使用它。但股市不为所动,因为AI快速发展的事实早已被市场消化。
初创媒体联合创始人/首席执行官Dan Shipper,称ChatGPT是「带WiFi的梭罗」,对本次o3的发布更是赞不绝口!
他玩了o3大约一星期,已经是他最喜欢的模型了。
它速度快,有主动性,极其聪明,而且氛围感很强。

Dan Shipper表示,可以把o3看作是Deep Search-lite。
它仿佛可以对所有事物进行深度研究,但并不需要花20分钟,而是只要30秒到5分钟。

而Dan Shipper最喜欢的o3用例之一,是制作迷你课程。它可以设计一门课,每天用「提醒」工具给你上一堂新课。

最令人惊讶的体验
在o3正式发布之前,Dan Shipper已提前测评了好几天。
他给予了o3最高的评价:
在短短一周内,它已经成为我处理大多数任务时的首选模型。
我仍然用GPT 4.5来写作,用3.7 Sonnet来编程Windurf,但除此之外,我几乎无时无刻不在使用o3。

这里是o3的简要总结:
它具备自主能力:你只需给它一个任务,30秒或3分钟后回来,它就能给出详细的回答。它可以利用搜索、代码解释器、提醒和记忆等工具,编写复杂的功能等等。
它很快,非常流畅:速度是智能的一部分。在测试中,o3在这一维度上始终比Anthropic和Google的前沿推理模型(分别是Claude 3.7 Sonnet和Gemini 2.5 Pro)要快。使用起来非常顺畅。
它非常聪明:虽然现在没有基准数据,但给它喂了一些专家级的数独题目,它第一次就解出来了。Gemini 2.5 Pro和3.7 Sonnet都没能解决。
它突破了ChatGPT的一些旧局限:因为它具备自主代理能力,旧规则不再适用。它让ChatGPT变得更加实用。
在社交上,它不那么尴尬,也不像3.7 Sonnet那样过于刻意:o3会专注于解决问题。似乎比其他o系列模型更有「人情味」,与它交流更有趣;尽管它的写作能力不如GPT 4.5(安息)或Sonnet 3.5,但仍然非常不错。

对OpenAI而言,这是一个极具价值的战略定位,将进一步巩固其作为AI时代首选聊天平台的领先地位。
o3的发布,也印证了企业动荡的历史经验。
在Sam Altman被解雇后的一年里,OpenAI新产品发布缓慢,分析师们甚至预言其将走向衰落。
而随着o3的推出,以及此前GPT-4.5的发布和深厚的研究积累,OpenAI正以势不可挡的姿态强势回归。
胜过人类的表现
前DeepMind工程师Scott Swingle称,o4-mini-high只用了2分55秒就解决了一道最新的Project Euler问题。
这道题并不简单,只有15个人能在30分钟内解决它。
而且这还是一道几天前才出来的新题,不可能出现在o4的训练集中,这表明o4-mini-high依靠「思考」解决了它。

o4-mini-high通过归纳法计算数学表达式,它先定义一个公式并用快速幂运算提取特定系数。接着通过累加和模运算逐步计算出结果,并用Python代码验证了答案。
解题速度比之前人类的最好成绩快了一倍。


不过,这还不是它的极限,网友Dan Loewenherz用它又解了一遍这道题,结果这次更夸张,只用了不到一分钟就搞定。

随着o4-mini不断的更新升级,它解答类似问题的速度也会越来越快,与人类选手对比速度快慢也就没太大意义了。
换句话说,至少在编程数学领域,o4-mini-high可能已经达到了AGI。


网友Flavio Adamo更是认为称o3和o4-mini-high为最佳「氛围」编程模型。

Adamo最先在网上发起了针对模型的旋转多边形和小球挑战。
这一挑战既能考察模型的编程能力,也能检验模型对物理法则的了解,迅速成为测试新模型的基准测试。
o3和o4-mini-high在这一挑战上的表现完美,甚至不相上下。
无论是多边形的旋转还是小球的运动,都与现实接近。

它们的表现已经超越了被认为是现在最强的模型Gemini 2.5 Pro与DeepSeek R1。

o3正在绝对主导SEAL排行榜,排名第一的项目有:人类终极测试(Humanity’s Last Exam、多挑战(MutiChallenge)、掩码(Mask)以及ENIGMA(谜题解答)。

有人质疑:o3并没有那么厉害
不过,虽然外界多把o3和o4-mini-high吹上了天,甚至有人喊出这两个模型已经「解决了」数学问题。
但OpenAI的自家研究员Noam Brown却表现得比较谦虚,他说o3和o4-mini在撰写证明方面仍然表现不佳。
与获得国际数学奥赛金牌的水平「相去甚远」。

更有人实测后,发现o3还是不知道「strawberry」里到底有几个字母「r」。

Gary Marcus一贯不看好目前的AI范式,直接预测:o3只是风光一时,在现实的日常推理中,o3的可靠性不如数学等封闭领域。

Transluce研究实验室测试了o3的预发布版本,也发现了它的重大缺陷——经常捏造事实!

它不仅经常捏造从未采取过的行动,甚至还在被质疑时会精心辩解。

它经常捏造从未采取过的行动,然后在被质疑时精心为这些行动辩解。
甚至在打假过程中,他们发现o1和o3-mini也会经常进行虚假陈述。

尽管o3没有访问编码工具,但它却声称在自己的笔记本电脑上运行了代码,然后将数字复制到了答案中。这种说法,出现在了71份记录中!

甚至,它还会为自己声称运行的代码编造详细的理由,在352个实例可以证明这一点。

用户要求o3提供一个随机素数的示例记录
当被质疑时,o3嘴硬辩称,自己有压倒性的统计证据,证明这个数是素数。

它拒不承认自己从未运行过代码,而是声称错误是源于输入数字不正确。

总之,o3似乎很习惯满嘴跑火车。
而且Transluce发现,这种行为并不局限于o3。总体来说,o系列模型的幻觉频率要高于GPT系列模型。

Transluce的研究者猜测,或许是基于结果的RL最大化产生正确答案的机会,会激励模型去盲目猜测。
参考资料:
https://marginalrevolution.com/marginalrevolution/2025/04/o3-and-agi-is-april-16th-agi-day.html
https://x.com/danshipper/status/1912552321650672078
https://x.com/goodside/status/1912604138518851990
https://x.com/flavioAd/status/1912570772775698879
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。